A detailed toolkit supporting consistent, practical, and scalable assessment of AI implementations across Canadian healthcare settings
Despite rapid AI adoption across Canadian health systems, as documented in our our environmental scan, there is no standardized, proportionate, lifecycle-based approach to evaluating clinical AI designed for delivery leaders. Existing frameworks focus on technical validation or governance intake, leaving a gap in practical decision support for scale. As a result, many AI initiatives stall between pilot and scale due to unclear evidence thresholds, fragmented governance, and misaligned financial accountability.
This toolkit is intended to support proportional, implementation-focused evaluation of clinical AI in healthcare delivery settings. It is designed to help organizations generate credible directional evidence to support operational decision-making, particularly in early-stage or resource-constrained environments. The toolkit complements, but does not replace, formal health technology assessment, academic reporting standards, regulatory review, or comprehensive economic evaluation methodologies.
“I really appreciated the detailed information and especially the implementation checklist and the case examples highlighting the importance of not only the technology but also the context.”—early user
“We used the KPI library to identify implementation evaluation metrics for a new AI tool. One thing that was particularly helpful is that we were able to use it in an iterative process and refine our metrics over a few meetings. Really great when working with a group of stakeholders with different levels of expertise and interests. The frameworks saved me personally time and effort!” —Kaitlyn Vingoe, RN, MN, Senior Director Practice Informatics, CPIO, Unity Health Toronto
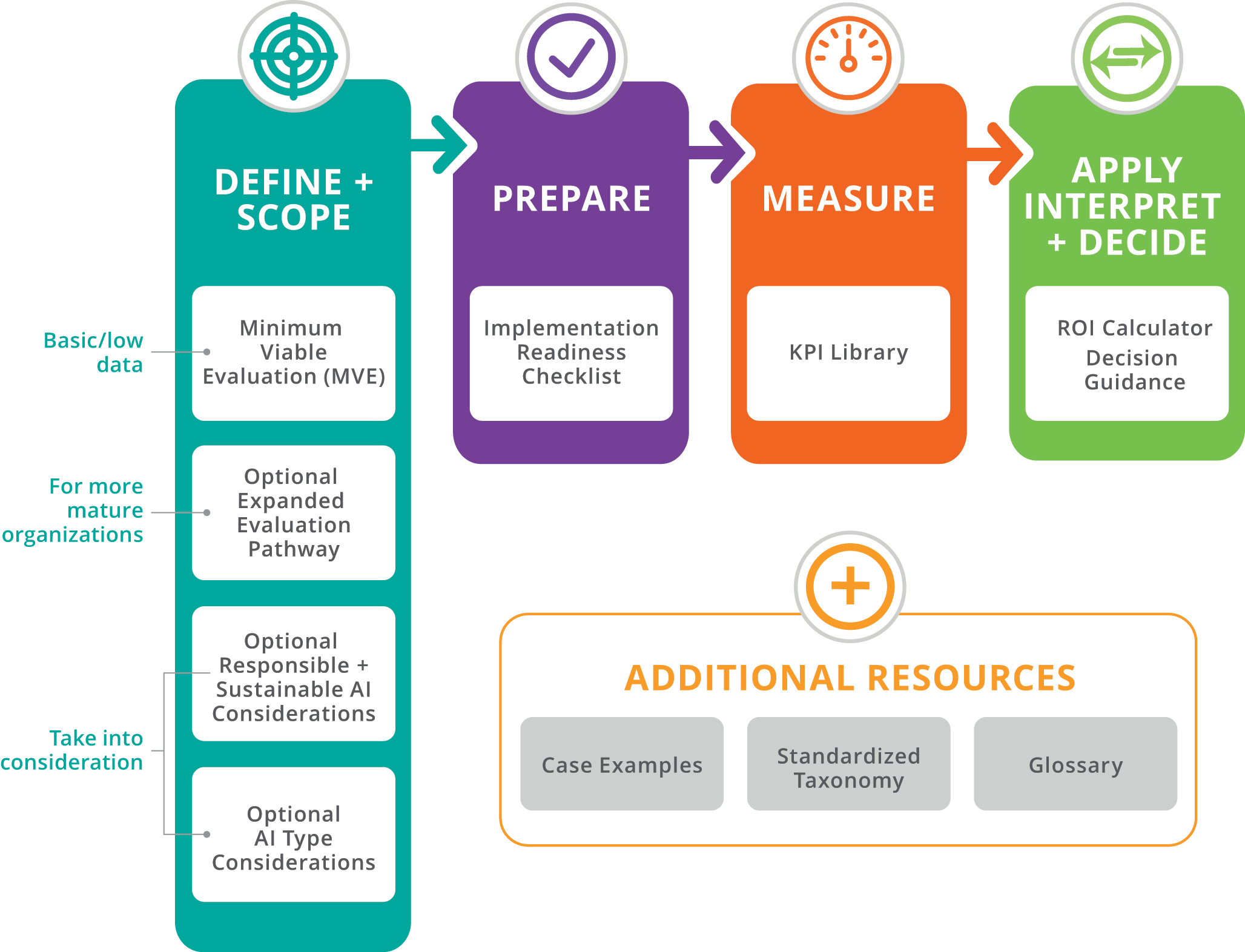
The toolkit brings together key elements needed to evaluate early impact, interpret results, and support responsible scaling. It provides a minimum evaluation that any organization can use, including those with limited analytic capacity, along with optional expanded components for teams that wish to conduct deeper analysis. Download the complete Clinical AI Toolkit (PDF)
How to use the toolkit
The toolkit components are designed to work together. The Minimum Viable Evaluation generates early signals of impact. The KPI Library helps structure what is measured. The ROI approach interprets these signals in terms of value. Together, these elements support structured decisions about whether to continue, refine, scale, or stop an AI tool.
Evaluation of clinical AI extends beyond performance metrics and financial return. Responsible use requires attention to safety, equity, transparency, sustainability, and long-term stewardship. These considerations are integrated throughout the toolkit and should be revisited over time as implementation matures.
Minimum Viable Evaluation
This evaluation provides the simplest consistent approach for early evaluation. It allows any organization, even those with limited analytic capacity, to capture a basic before and after assessment and generate an early sense of impact.
Minimum Requirements (applies to all organizations)
The following elements should be included in every evaluation, regardless of organizational size or analytic capacity:
- Confirmation that evaluation activities use data already approved for clinical or operational use and do not introduce new data uses or privacy risks
- Identification of first- and second-order impacts relevant to the implementation
- A simple estimate of organizational effort and person-hours required for implementation and early use
- Basic model oversight and early feedback-data assessment to verify correctness and alignment with clinician judgment
- Completion of the minimum implementation-readiness checklist (workflow fit, data basics, staff comfort, time capacity, context factors, and simple evaluation feasibility)
- A brief environmental sustainability note where relevant (for example, computing intensity or carbon considerations)
- In most cases, a simple before-and-after comparison using two to four indicators and a brief narrative summary is sufficient for early-stage evaluation.
Optional Expanded Evaluation
The Expanded Evaluation builds directly on the Minimum Viable Evaluation and is optional for organizations with greater analytic capacity or higher-risk implementations.
Organizations with greater analytic capacity, richer data environments, or more complex implementations may choose to complete additional analyses. These optional components build on the Minimum Viable Evaluation and provide deeper insight into performance, context, and financial return. Find details of the Optional Expanded Evaluation in the Clinical AI Toolkit PDF.
Optional Responsible and Sustainable AI Considerations
For many software-as-a-service tools, a formal sustainability assessment may not be required. In these cases, teams may simply confirm that vendor infrastructure, support, and licensing arrangements are sufficient for continued use. Find details of the Responsible and Sustainable AI Considerations in the Clinical AI Toolkit PDF.
Optional AI Type Considerations
The evaluation approach in this toolkit applies across AI implementations. However, different AI types may warrant emphasis on different risks, performance indicators, and oversight considerations. The following table highlights common areas of nuance. This section does not introduce new requirements. Find further details of the Optional AI Type Considerations in the Clinical AI Toolkit PDF.
Implementation Readiness Checklist
The checklist outlines the basic conditions that support successful adoption and practical evaluation of an AI tool. It is designed to help organizations of all sizes, including small clinics with limited analytic capacity, determine whether they have the essential groundwork in place before beginning measurement. It ensures that workflow fit, data basics, staff comfort, and simple feasibility have been considered.
- Workflow Fit – The team understands how the AI tool fits into the daily workflow, who will use it, and at what point in the patient encounter it is accessed. A few test cases have been tried to ensure the tool does not add friction or unnecessary steps. Have the workflow changes required for the AI tool to deliver its intended benefit been identified, documented, and communicated to affected staff?
- Data Basics – The organization has the minimum data required for the tool to function and can capture a simple baseline for one or two indicators using existing data sources. This assumes that existing organizational privacy, consent, and data-use approvals apply and that no new data uses are introduced for evaluation purposes.
- Clinician and Staff Comfort – Clinicians and staff understand what the tool does and does not do and know how to note issues, unexpected outputs, or early observations during initial use.
- Time and Capacity – A short period of protected time exists to monitor early use and reflect on impacts. The team can assess whether the tool appears to save time or effort relative to the change required to adopt it.
- Context Factors – Recent changes in schedules, staffing levels, patient volumes, or service patterns are documented, as these factors may influence evaluation results during the baseline or early measurement period.
- Equity and Experience – The tool appears to work consistently across the typical patient population served by the organization and does not hinder clinician or staff workflow experience.
- Evaluation Feasibility – The organization has selected one or two practical indicators to measure, identified a simple before–after assessment period, and determined who will summarize results in a brief narrative.
- Change Management and User Readiness – The organization has identified what orientation, training, communication, and support will be needed for clinicians, staff, and where relevant, patients or other end users during early implementation.
KPI Library
The KPI Library is a structured set of metrics organizations can select from when designing an AI evaluation approach. These KPIs support both the Minimum Viable Evaluation and the Expanded Evaluation. Organizations can select from this list or add their own indicators if needed. This is a starter library, and the list can expand and refine over time to reflect additional use cases, population contexts, and the needs of smaller or lower-data organizations.
Clinical AI Evaluation Toolkit: KPI Library
| Metric, KPI, ROI Input Name | Metric Category | Common Across Most AI Types? | Evaluation Tier | Primary Domain | Secondary Lens (optional) | Plain language definition | What this measures or represents | Why this metric matters | How it is typically measured or estimated | Data Intensity | Suitable for Low-Data settings | Used as a KPI, ROI Input, or Both | Key Sources of Uncertainty | Notes | Source ( Optional) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Techical/Model Performance | Yes | Minimum (Low-Data Feasible) | Clinical | The proportion of AI outputs that are correct when compared to a reference standard. | How often the AI produces accurate results relative to expected or verified outcomes. | Accuracy directly influences clinical safety, trust, and downstream decision quality. | Comparison of AI outputs against chart review, expert adjudication, or validated reference datasets. | Low | Yes | KPI | Attribution to AI versus other workflow or staffing changes; Seasonality or volume fluctuations. | |||
| AI Recommendation Override Rate | User Experience | Yes | Minimum (Low-Data Feasible) | Operational | Safety | How often users choose not to follow AI recommendations, indicating trust, fit, or concern. | Human oversight behavior | High override rates may signal safety or usability issues | System logs, user self-report | Low | Yes | KPI | Incomplete logging or data capture; Variation across sites, users, or patient groups. | FUTURE-AI Guidelines | |
| Click Through Rate (CTR) | Implementation Evaluation | Context-specific | Advanced (High Analytic Capacity) | Operational | Represents the percentage of people who take action after an event | showing exposure leads to capability engagement | Can be used to measure adoption rate, action taken rate, and alert engagement rate and ignore rate. | Number of actions taken divided by number of exposures. | Low | Yes | Both | Incomplete logging or data capture; Infrastructure variability. | |||
| Clinical Use Appropriateness | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Clinical | Safety | The extent to which the AI tool is used for the clinical purposes and patient groups it was intended for. | Alignment between intended and actual clinical use | Helps prevent unsafe or inappropriate application of AI | Chart review, usage audits, clinician self-report | Low | Yes | KPI | Incomplete logging or data capture. | FUTURE-AI Guidelines | |
| Clinical Workflow Fit | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Operational | How well the AI fits into existing clinical workflows without disrupting care delivery. | Ease of integration into care processes | Poor workflow fit reduces adoption and effectiveness | Workflow observation, user feedback | Low | Yes | Both | Incomplete logging or data capture; Variation across users. | FUTURE-AI Guidelines | ||
| Clinician-Reported Clinical Value | User Experience | Yes | Minimum (Low-Data Feasible) | Experience (clinician or patient) | Clinical | Clinicians’ assessment of whether the AI meaningfully supports clinical decision-making or care delivery. | Perceived contribution to clinical decision-making | Captures value in settings where outcome data are limited | Clinician surveys or structured interviews | Low | Yes | Both | Self-report bias; Small sample size. | FUTURE-AI Guidelines | |
| Coherence / Fluency | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Experience (clinician or patient) | Quality | Clarity and logical order of a response. | Measures whether the answer stays on track and fits, or makes logical sense from beginning to end. | Represents if the AI is able to stay on topic as value of output is lost if response is poorly structured or disjointed. | Typically measured through human and user ratings. Advanced tools can measure contraction detection | High | No | KPI | Small sample size; Variation across evaluators. | ||
| Contextual Suitability | Implementation Evaluation | Expanded (Moderate Capacity) | Operational | Equity | How well the AI works across different care contexts, resource levels, or local practices. | Context sensitivity | Supports transferability across settings | Qualitative assessment, pilot feedback | Medium | No | KPI | Variation across sites, users, or patient groups; Small sample size. | FUTURE-AI Guidelines | ||
| Cost of Implementation | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Financial | Operational | The total cost required to introduce the AI tool, including licensing, setup, and staff time. | Upfront financial investment | Critical for budgeting and approval decisions | Budget records, procurement data | Low | Yes | Both | Attribution to AI versus other workflow or staffing changes; Seasonality or volume fluctuations. | FUTURE-AI Guidelines | |
| Downstream Benefits | Implementation Evaluation | Yes | Expanded (Moderate Capacity) | Financial | Operational | Secondary or indirect benefits that occur as a result of initial improvements enabled by an AI solution. | The broader unexpected effects that follow primary gains. | Many AI benefits are not directly measurable but materially increase total value over time if acknowledged in decision-making | Estimated through historical data, modeling, or expert judgment | High | No | Both | Small sample size; Model drift or system updates over time. | Bharadwaj P, Nicola L, Breau-Brunel M, Sensini F, Tanova-Yotova N, Atanasov P, Lobig F, Blankenburg M. Unlocking the Value: Quantifying the Return on Investment of Hospital Artificial Intelligence. J Am Coll Radiol. 2024 Oct;21(10):1677-1685. doi: 10.1016/j.jacr.2024.02.034. Epub 2024 Mar 16. PMID: 38499053. | |
| Ease of Use | User Experience | Yes | Minimum (Low-Data Feasible) | Experience (clinician or patient) | Trust | How easy and intuitive the AI tool is for users to operate within their normal workflow. | User perception of simplicity, clarity, and effort required to use the tool. | Tools that are difficult to use reduce adoption, increase frustration, and limit realized value. Ease of use directly influences sustained engagement and trust. | Short user surveys (for example, 1–5 rating scale), structured feedback questions, or brief post-implementation interviews. | Low | Yes | KPI | Self-report bias; small sample size; early novelty effects. | ||
| Error Rate | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Clinical | Safety | The frequency with which the AI produces incorrect outputs relative to a defined reference standard. | The proportion of AI outputs that are incorrect when compared to expected, verified, or gold-standard results. | A higher error rate increases clinical risk, reduces trust, and may undermine adoption. Monitoring error rate supports early detection of performance issues. | Comparison of AI outputs against chart review, expert adjudication, or validated reference datasets; expressed as a percentage of incorrect outputs. | Low | Yes | KPI | Incomplete logging or data capture; Small sample size. | https://www.producttalk.org/glossary-ai-error-rate/?srsltid=AfmBOor1H8m7GqY5Ig1tFoJ_3O5kp81g9aoV3tWOfkzbQdlgmJkVm4lI | |
| Hours Saved | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Operational | Financial | Represents aggregate time savings across the organization. The total staff time saved across a defined period due to AI-assisted or automated tasks. | The time returned to the organization. | Faster service delivery | Time per task comparison, process step reduction, increase productivity | Low | Yes | Both | Small sample size; Reference standard limitations. | ||
| Implementation Effort | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Operational | Financial | The amount of staff time and organizational effort required to implement and maintain the AI tool. | Organizational burden of adoption | High effort can limit scalability | Project tracking, staff time estimates | Low | Sometimes | Both | Attribution to AI versus other workflow or staffing changes; Variation across sites, users, or patient groups. | FUTURE-AI Guidelines | |
| Intended Population Coverage | Implementation Evaluation | Expanded (Moderate Capacity) | Equity | Operational | The extent to which the AI reaches the populations and settings it was designed to support. | Reach across intended populations | Uneven reach can worsen inequities | Deployment records, site reports | Medium | No | Both | Small sample size; Variation across sites, users, or patient groups. | FUTURE-AI Guidelines | ||
| Model Latency | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Operational | Experience | The time required for the AI system to generate a response after receiving a request. | This measurement represents system performance, infrastructure performance. A low latency means higher adoption, greater impact, stronger ROI. A high latency means low adoption, low impact, and weak ROI | Model latency matters because speed determines usability. If AI responses are slow, adoption drops, workflow efficiency declines, and expected ROI is not realized. | The time it takes to generate a response. Response end time minus response start time. Many different types of latency to measure. End to end, model processing time (backend latency), time to first token (this is for streaming systems)..... | Low | Yes | KPI | Small sample size; Variation across evaluators. | ||
| Observed Harm or Safety Concerns | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Clinical | Safety | The presence and frequency of reported patient safety concerns or unintended negative effects related to AI use. | Patient safety risks linked to AI | Early detection of harm supports safer deployment | Incident reports, safety logs, qualitative feedback | Low | Yes | Both | Small sample size; Inconsistent documentation quality. | FUTURE-AI Guidelines | |
| Ongoing Operating Cost | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Financial | Sustainability | The recurring costs needed to maintain the AI tool over time. | Long-term financial burden | Affects sustainability and scale-up | Financial tracking, vendor contracts | Low | Yes | Both | Attribution to AI versus other workflow or staffing changes; Seasonality or volume fluctuations. | FUTURE-AI Guidelines | |
| Perceived Value for Money | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Financial | Experience | Decision-makers’ assessment of whether the benefits of the AI justify its costs. | Overall value judgment | Supports go/no-go and renewal decisions | Leader survey / structured assessment | Medium | Yes | Both | Self-report bias; Attribution to AI versus other financial or operational changes. | FUTURE-AI Guidelines | |
| Recommendation Acceptance Rate | User Experience | Context-specific | Advanced (High Analytic Capacity) | Operational | Trust | The proportion of AI-generated recommendations that are accepted and acted upon by users. | The rate at which AI advice translates into real-world clinical or operational action. | AI only creates value when recommendations influence behavior. A high acceptance rate may signal workflow fit and trust. A low acceptance rate may indicate usability issues, misalignment with clinical judgment, or weak change management. | Number of accepted recommendations divided by total recommendations generated within a defined period. | Medium | No | Both | Attribution to AI versus concurrent workflow or staffing changes; variation across users or sites; incomplete logging. | ||
| Reported Equity Concerns | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Equity | Risk | The presence of reported concerns that the AI performs differently or creates barriers for certain groups. | Perceived inequitable impacts | Helps identify emerging bias in low-data settings | User feedback, stakeholder reports | Low | Yes | KPI | Small sample size; Variation across sites, users, or patient groups. | FUTURE-AI Guidelines | |
| Request throughput | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Operational | Time | The number of requests an AI system can process within a defined time period. | The system’s capacity to handle workload volume under typical or peak conditions. | If throughput is too low relative to demand, response times increase, adoption drops, and expected operational or financial benefits may not be realized. Adequate throughput supports scalability and reliability. | Total number of requests processed per unit of time (for example, requests per minute or requests per hour), based on system logs under normal or peak usage conditions. | Low | Yes | KPI | Incomplete logging; variability in workload mix; infrastructure differences across environments. | ||
| Retrieval Latency | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Operational | Time taken for a system to find and return relevant result after a query | How quickly the system can find the information the AI needs. | Poor indexing increases retrieval time and will directly impact total response time. | Total AI response time = retrieval time + model generation time | Low | Yes | Both | Incomplete logging or data capture; Infrastructure variability. | |||
| Return Period | Implementation Evaluation | Yes | Advanced (High Analytic Capacity) | Financial | The time period after deployment of the AI tool until revenue surpasses implementation expenses. | How long it would take for the investment in the AI tool to pay itself and generate financial benefit | Assists in understanding cost burden until financial recuperation from implementing a tool | Calculated by dividing total implementation and operating costs by estimated annual net benefit. | Low | Yes | ROI Input | Attribution to AI versus other workflow or staffing changes; Variation across sites, users, or patient groups. | |||
| Safety | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Clinical | Safety | The extent to which AI outputs avoid generating harmful, misleading, biased, or clinically unsafe information. | Frequency or presence of unsafe AI outputs or clinically inappropriate recommendations. | Unsafe outputs can lead to clinical safety risk, regulatory issues, legal risk, reputational damage, and trust. | Harm incident rate, hallucination rate, compliance rate, and bias detection metrics. | Medium | Sometimes | KPI | Small sample size; model drift or system updates over time. | ||
| Summarization Quality | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Experience (clinician or patient) | Clinical | Measures how the AI summary captures the most important information from a longer source, without leaving critical details or adding incorrect information. | This measurement will help understand if the AI distorts meaning, introduces new information, preserves context, and includes key points of prompt. | This measurement is often evaluated alongside time savings because low-quality summaries increase editing effort and reduce realized efficiency. | Measured using coverage scores, calculated as the proportion of key facts included relative to total critical facts. | High | No | ROI Input | Attribution to AI versus other workflow or staffing changes; Variation across sites, users, or patient groups. | ||
| System Availability | Implementation Evaluation | Yes | Expanded (Moderate Capacity) | Operational | Experience | The proportion of time the AI tool is accessible and functioning when users need it. | Technical reliability | Unreliable systems undermine trust and use | System logs, uptime monitoring | Low | Yes | KPI | Incomplete logging or data capture; Infrastructure variability. | FUTURE-AI Guidelines | |
| Task Completion Time / Time to Decision | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Operational | Financial | Represents time per individual task. The average time required to complete a task with the AI compared to without it. | Change in task duration | Shows whether AI improves operational efficiency | Before–after comparisons, sampling | Medium | No | ROI Input | Attribution to AI versus other workflow or staffing changes; Variation across sites, users, or patient groups. | FUTURE-AI Guidelines | |
| Text Quality or Quality Proximity | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Experience (clinician or patient) | Quality | Measures how clear, accurate, complete, and useful AI generative text is for its intended purpose. | Measures if the output is good enough to use if its factually correct and relevant to the input. | High quality proximity leads to reduced time editing, faster decision time, lower rework, improved consistency. Lower quality creates hidden labor costs, safety risks, and trust issues and adoption decline. | Typically measured by the percentage of outputs used without modification. | High | No | Both | Small sample size; Variation across evaluators. | ||
| Thumbs Up / Down Feedback | User Experience | Yes | Minimum (Low-Data Feasible) | Experience (clinician or patient) | Trust | User rating on if they found the AI response helpful or not | The satisfaction of users with the system | Provides a simple, scalable signal of perceived usefulness and early user trust. | Binary or scaled in-system feedback collected during or immediately after AI interaction. | Low | Yes | Both | Self-report bias. | ||
| Time on Site (Session Duration) | User Experience | Context-specific | Advanced (High Analytic Capacity) | Operational | Experience | Amount of time a user spends actively using the system during a single session | Time spent in user engagement | Can help to understand how users are engaging | using system logs that record when a user starts and ends a session, | Low | Yes | Both | Incomplete logging or data capture; Variation across users. | ||
| Token throughput | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Operational | The number of tokens the model can generate per second under defined workload conditions. | A measurement of speed and processing capacity | Represents the efficiency of an AI system | Number of tokens generated per unit of time under defined workload conditions. | Medium | No | Both | Incomplete logging or data capture; Infrastructure variability. | |||
| Training Completion | Implementation Evaluation | Yes | Minimum (Low-Data Feasible) | Operational | Safety | The percentage of intended users who have completed basic training on how to use the AI tool safely. | User preparedness | Training supports safe and effective use | Training records | Low | Yes | KPI | Incomplete logging or data capture. | FUTURE-AI Guidelines | |
| User Adoption Rate | User Experience | Yes | Minimum (Low-Data Feasible) | Experience (clinician or patient) | Operational | The percentage of new users who adopt the technology. | Represents that the solution fits users' workflow | Helps identify if tool/capability has moved from availability to usability and sustainability. | Percentage of users that use the AI capability within a defined period | Low | Yes | Both | Incomplete logging or data capture; Variation across sites, users, or patient groups. | ||
| User Satisfaction | User Experience | Yes | Minimum (Low-Data Feasible) | Experience | Trust | Users’ overall satisfaction with the AI tool, including ease of use and perceived usefulness. | User trust and acceptance | Trust is critical for sustained use | Surveys, feedback forms | Low | Yes | KPI | Self-report bias; Small sample size. | FUTURE-AI Guidelines | |
| Variability Reduction | Implementation Evaluation | Context-specific | Expanded (Moderate Capacity) | Clinical | Trust | Making the system produce more consistent and predictable outputs. | Consistency | Consistent outputs improve reliability, trust, and safety | Comparison of standard deviation or range in outputs before and after implementation; or structured review of output consistency across similar cases. | Medium | No | KPI | Small sample size; Inconsistent documentation quality. | ||
| Verbosity | Techical/Model Performance | Context-specific | Advanced (High Analytic Capacity) | Experience (clinician or patient) | Quality | How long an AI's output is. | This measures how much text or explanation an AI system produces when responding to a request. | It can be tracked to understand clarity, efficiency, cost, and user experience. | Typically measured by average word count per response. | Medium | No | KPI | Attribution to AI versus other financial or operational changes; Seasonality or volume fluctuations. | ||
| Workflow Adaptation Time | Implementation Evaluation | Yes | Expanded (Moderate Capacity) | Operational | Experience | The time required for clinicians or staff to integrate the AI tool into routine workflows. | The amount of time required for clinicians or staff to become comfortable using the AI tool as part of routine workflow, including adjustments to documentation, decision processes, or task sequencing. | Tools that require long adaptation periods may reduce adoption and delay benefits. | User surveys, observational workflow studies, or time-to-stable usage estimates. | Medium | Sometimes | KPI | Variation across users, services, or sites; difficulty separating AI learning curve from broader workflow change. |
ROI Calculator
This calculator provides high-level directional estimates intended for early-stage evaluation. Results depend on clearly defined perspective, comparator, time horizon, and input assumptions. Estimates should be interpreted cautiously and are not a substitute for formal economic evaluation.
Download the Excel spreadsheet at the link below.
Decision Guidance
The outputs of this toolkit are intended to support decision-making, not just measurement. At this stage, consider adoption, risk signals, and value together to determine the most appropriate next step.
Continue / Scale
Proceed with broader implementation or expansion when:
- Adoption is meaningful and showing signs of growth
- No significant unresolved risks are identified (for example, quality, safety, workflow, or equity concerns)
- Directional ROI is positive and supported by early signals
- Continue with Conditions
Proceed with targeted adjustments and ongoing monitoring when:
- Adoption is uneven or concentrated within a subset of users
- Specific risks or limitations are identified (for example, content quality, editing burden, workflow fit, or equity considerations)
- Directional ROI is positive but dependent on key assumptions or incomplete data
- Focus on addressing identified gaps before scaling further.
Pause / Reassess
Pause further rollout and reassess when:
- Adoption is low or declining
- Significant risks or concerns remain unresolved
- There is no clear or consistent signal of value
- Additional data collection, workflow adjustment, or tool refinement may be required before proceeding.
Important considerations:
- These are guides, not thresholds or rules
- Decisions should not rely on a single input (for example, ROI alone)
- Early findings are directional and should be revisited as more data becomes available
- Ongoing oversight is expected, with reassessment at defined intervals (for example, 3 to 6 months)
Case Examples
Case Examples illustrate how evaluation concepts and value interpretation may be applied in different clinical and operational contexts. The examples are intentionally illustrative and directional. They are not validated case studies and do not represent formal outcome evaluations. Their purpose is to demonstrate how organizations might approach early assessment, interpret signals of impact, and identify contextual factors that influence results. Each example also highlights contextual factors such as workflow integration, user training, or operational readiness that can influence early evaluation results. These examples can be used alongside the MVE, KPI selection, and ROI interpretation steps to guide application. Find all case examples in the Clinical AI Toolkit PDF.
Standard Taxonomy and Glossary
These plain-language term definitions are provided as supporting materials for the Clinical AI Evaluation Toolkit. They are intended to promote consistent interpretation of key evaluation and ROI concepts across organizations. The definitions are practical and directional. They are not formal technical or academic definitions. Find the Taxonomy and Glossary in the Clinical AI Toolkit PDF.
This work is being championed by Dr. Tania Tajirian, Chief Health Information Officer (CHIO) and Chief of Hospital Medicine at the Centre for Addiction and Mental Health (CAMH) through the AI in Action Working Group.
We extend our sincere thanks to the CHIEF Executive Forum working group members whose insights and leadership shaped this effort:
- Andrew Nemirovsky, Interlace Health
- Andrew Pigou, Baycrest
- Amelia Hoyt, Michael Garron Hospital
- Angel Arnaout, PHSA
- Attila Farkas, Infoway
- Brett Taylor, Health Canada
- Bruno Gagnon, Health Canada
- Chandi Chandrasena, OntarioMD
- Chris Sulway, OntarioMD
- Christine Grimm, HealthTech
- Christine LaRocque, Healthcare Excellence Canada
- Dawn Lake, Doctors of BC
- Elizabeth Keller, Amazon Web Services
- Justin Wolting, eHealth Centre of Excellence
- Karen Hay, Salesforce
- Keltie Jamieson, Bermuda Hospitals Board
- Marc Koehn, Accenture
- May Tuason, PHSA
- Pippy Scott-Meuser, Centre for Effective Practice
- Prabhjot Gill, PHSA
- Sarah Muttitt, SickKids
- Scott McMillan, Cercle Groupe
- Sonia Pagliaroli, Oracle
We also gratefully acknowledge the contributions of these Emerging Professional volunteers:
- Anjana Ravi, Centre for Effective Practice
- Dersha Uthayakumaran, Centre for Effective Practice
- Emilia Jankowicz, CAMH
- Emma Gratzer, CAMH
- Kirti Minocha, Bermuda Hospitals Board
- Thish Rajapakshe, University of Queensland
- Valentina Gnanapragsam, Centre for Effective Practice
Contribute to Shared Learning
Many organizations are facing similar questions as they begin evaluating clinical AI. If you have applied the Clinical AI Toolkit, please share a summary of your experience with chief@digitalhealthcanada.com. Include a brief description with slides or internal materials, or simply share a high-level use case with KPIs, signals, decisions, and lessons learned. Of particular interest: what you chose to measure, what signals emerged early, and how those signals informed your decision-making. Submissions can be anonymized. Share your experience at chief@digitalhealthcanada.com.